迈进Makefile的世界(入门)

简介
Linux的make程序用来自动话编译大型源码,实现只需要一个make执行就可以全自动完成。
make能自动化完成,是因为项目路径下提供了一个Makefile文件,由该文件负责告诉make,应该去编译和链接该项目程序。
make起初只针对C语言开发,但它实际应用并不限定C语言,而是执行Linux命令去应用到任意项目,甚至不是编程语言。
此外
make主要应用与Unix/Linux环境的自动化开发,所以掌握Makefile,可以更好的在Linux环境下做开发,为后续开发Linux内核做好准备(嵌入式方向必备的东西)
安装make
首先你要有一个Linux系统,这里可以用WSL或者VMware,当然不建议直接装个Linux系统,因为大多数还是用Windows比较多一些。
我们以Ubuntu为例,在Linux命令行下,使用apt安装make以及GCC工具链
sudo apt update
sudo apt install build-essential
安装完成后,可以输出命令make -v验证,得到的输出应该是GNU Make的版本;
输入gcc --version验证GCC工具链,得到的输出也应该是gcc的版本。
GCC可以自己了解一下,后期可以计划单独列一个学习教程,蛮实用的
Makefile基础
在Linux环境下,我们输入make命令时,它就在当前项目目录查找一个名为Makefile的文件,根据这个文件定义的规则,自动化的执行任意命令,包括编译命令。
规则
Makefile是由若干条规则构成,每一条规则支持一个目标文件(Target),若干个依赖文件,以及生成目标文件的命令。
生成a.out依赖main.c,的规则如下
#目标文件: 依赖文件
a.out: main.c
gcc main.c -o a.out
#注意:命令要用tab缩进
规则的格式为目标文件: 依赖文件1 依赖文件2,以Tab开头的是命令,用来生成目标文件。用什么方式生成目标文件make并不关心。
注意 在Makefile中,命令必须以Tab开头,不能是空格
在make执行时,默认执行第一条规则,所以要注意规则先后顺序。
make默认执行第一条规则,但如果依赖文件并不存在时,故需要先执行创建依赖文件的规则。
可见,Makefile定义了一系列规则,每个规则在满足依赖文件的前提下执行命令,就能创建出一个目标文件。
把默认执行的规则放在第一条,其他的规则顺序是无关紧要的,因为
make执行时会自动判断依赖,并且make会打印出每一条执行的命令,便于调试。
在make中如果目标文件的创建时间晚于依赖文件的最好修改时间,会提示目标文件已经是最新文件。
$ make make: `x.txt' is up to date.
修改依赖文件之后才会触发目标文件的更新。
在编译大型程序的时候,全量编译往往比较耗费时间,甚至需要几小时。非常不方便调试,但是用Makefile实现增量编译就节省了编译的时间。
但是make本身不会去检查逻辑的正确性。
Makefile的常用命令和选项
make
默认执行Makefile文件中的第一个目标。
make clean
通常情况下用于清楚编译过程中产生的中间文件和最终生成的目标文件。
make -f file
指定一个非标注名称的Makefile文件,不使用Makefile的默认标准名称。
目录下有一个altmakefile的Makefile文件
make -f altmakefile
make -n
只打印要执行的命令单步执行
make -s
执行命令,但不显示执行命令的指令
伪目标(.PHONY)
如果在make过程中,出现了我们自动生成的文件,这些文件是因为编译生成,可以正常的删除。
删除的时候,我们不希望手动一个个删除,那么这时就可以编写一个clean规则来删除它们。
clean:
rm -f m.c
rm -f c.h
clean与前面的规则不同,其没有依赖文件,所以要执行clean,必须要执行make clean才可以。
执行过程就是,运行make clean的时候,make会检查是否存在名为clean的文件?
- 不存在就执行这个命令。
- 如果目录下创建了clean的文件,Make就会认为"目标已经存在并且没有过期",所以就不会执行删除命令了。
这时候,就要提到
.PHONY的作用了,将clean不再视为一个文件,而是一个伪目标。
.PHONY: clean
clean:
rm -f m.c
rm -f c.h
成熟的项目通常会认为clean、install这些约定俗称的伪目标,所以一般clean不需要.PHONY,除非有人恶意修改。
执行多条命令
一个规则下可以执行多条命令:
cd:
pwd
cd ..
pwd
liustu@MrLiu:~/gitte$ make cd
pwd
/home/liustu/gitte
cd ..
pwd
/home/liustu/gitte
当我们执行make cd的时候会发现两次输出的pwd是一样的,这是因为make针对每一行命令,都会创建一个单独的shell环境,所以并不会影响当前输出的shell目录。
解决办法就是多条语句通过;分隔,写到一行(可以用\把一行拆成多行)
cd:
pwd;\
cd ..;\
pwd
这样只要保证命令在同一行,那么他们就在同一个shell环境了。
liustu@MrLiu:~/gitte$ make cd
pwd; \
cd ..; \
pwd
/home/liustu/gitte
/home/liustu
另一条执行多条命令是&&,他的好处是当前面的命令失败的时候,后续命令就不会继续执行。
cd:
cd asd && pwd
liustu@MrLiu:~/gitte$ make cd
cd asd && pwd
/bin/sh: 1: cd: can't cd to asd
# 前面的cd失败了,就不会执行后面的命令了
make: *** [Makefile:2: cd] Error 2
控制打印
默认情况下,make会打印出它执行的每一条命令。如果我们不想打印某一条命令,可以在命令前加上@,表示不打印命令,但是仍然会执行。
output:
@echo '此乃刘同学'
echo 'liustu.com.cn'
liustu@MrLiu:~/gitte$ make output
此乃刘同学
liustu.com.cn
控制错误
make在执行命令时,会检查每一条命令的返回值,如果返回错误(非0),就会中断执行。
如果我们先要忽略这个情况,即这一条命令错误了,但是不影响后面的命令,可以在要忽略的错误命令前加上-
nosee_error:
-rm liustuwansuiwansuiwansui.txt
echo 'ok'
liustu@MrLiu:~/gitte$ make nosee_error
rm liustuwansuiwansuiwansui.txt
rm: cannot remove 'liustuwansuiwansuiwansui.txt': No such file or directory
make: [Makefile:2: nosee_error] Error 1 (ignored)
echo 'ok'
ok
编译C程序
在Makefile分享中,提一下C语言编译的流程,因为其实嵌入式C开发比较多一些,所以写的Makefile也是对C比较多一些。(好吧就是想提一下,没有原因)。
GCC后期再将,现在先了解吧
C的编译通常分为两步
- 将所有的
.c文件编译为.o文件 - 将所有的
.o文件链接为最终可执行文件
现在我们有hello.c、hello.h、main.c。
那么我们很容易就知道需要生成那些文件了。
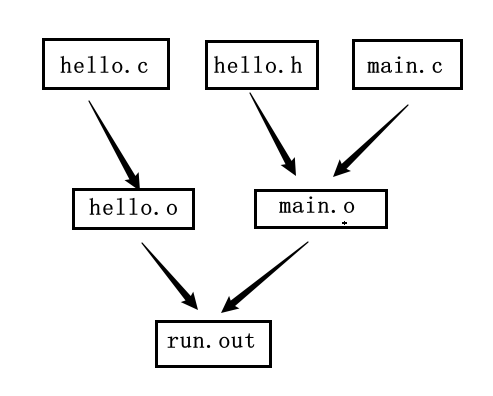
假定最后要生成的可执行文件是run.out,中间步骤还有生成hello.o、main.o,其中两个文件各有自己的依赖文件。那么我们就可以写出Makefile
# run.out 依赖两个.o文件
run.out: main.o hello.o
# 生成目标文件的命令是,链接两个.o文件生成.out
gcc -o run.out main.o hello.o
# 那么两个.o文件怎么来的?makefile自动生成的
# main.o依赖main.c和hello.h
main.o:main.c hello.h
# 这个命令就是平常你要手敲的东西
gcc -c main.c
hello.o: hello.c hello.h
gcc -c hello.c
# 当然也要有clean的部分
clean:
#直接删除所有.o和生成的可执行文件
#rm *.o run.out
$(RM) *.o run.out
执行make
$ make
cc -c hello.c
cc -c main.c
cc -o world.out hello.o main.o
如果此时修改hello.c,再执行make的时候,会仅仅重新编译了hello.c,并没有重新编译main.c,然后重新生成run.out
使用隐式规则
之前提到make是为了编译C语言而设计的,为了避免重复编译.o文件的规则,make内置了隐式规则,即遇到需要.o文件时候,如果没有找到对应的规则,就自动应用隐式规则。
xyz.o: xyz.c
cc -c -o xyz.o xyz.c
但是隐式规则无法最终.h文件的修改,如果我们修改了.h文件的定义,那么就不会因为.h变化而重新编译。
Makefile中的变量
$(变量名)
在Makefile中会重复写很多文件名,当写错了,或者要改名的时候,就要全部替换,这样非常麻烦。
make使用变量来解决这个问题。
比如我们脚本中,run.out出现的次数比较多,因此,可以定义一个变量来替换它:
TARGET = run.out
$(TARGET): main.o hello.o
gcc -o $(TARGET) main.o hello.o
clean:
$(RM) *.o $(TARGET)
变量定义用变量名 = 值或者变量名 : 值,通常变量名全大写。引用变量勇$(变量名)。
那么我们把依赖文件也替换一下:
TARGET = run.out
OBJS = main.o hello.o
$(TARGET): $(OBJS)
gcc -o $(TARGET)$(OBJS)$
clean:
$(RM) *.o $(TARGET)
如果有一个方式能让make自动生成hello. main.o这个列表就可以了。这里的每个.o文件是由对应的.c文件编译产生的,因此可以让make先获取.c文件列表,再替换,得到.o文件列表。
那么这里介绍一个函数patsubst,以及wildcard。
- wildcard: 用于扫描当前目录下所有某种类型的文件
- patsubst: 字符替换,如用于替换文件后缀
# $(wildcard *.c) 列出当前目录下的所有 .c 文件: hello.c main.c
# 用函数 patsubst 进行模式替换得到: hello.o main.o
OBJS = $(patsubst %.c,%.o,$(wildcard *.c))
TARGET = run.outg
$(TARGET): $(OBJS)
gcc -o $(TARGET) $(OBJS)
clean:
$(RM) -f *.o $(TARGET)
自动变量
自动变量主要包括$@,$<,$~:
$@: 表示规则中的目标$<: 表示第一个依赖文件$~: 表示所有的依赖文件
使用模式规则
%的使用
模式规则允许使用%通配符来匹配文件名,从而可以为自足文件定义相同的编译规则。
CC=gcc
%.o: %.c
$(CC) -c $< -o $@
在make中,我们可以自定义模式规则,允许make匹配模式规则,如果匹配了,就自动创建一条模式规则。
OBJS = $(patsubst %.c,%.o,$(wildcard *.c))
TARGET = run.out
$(TARGET): $(OBJS)
cc -o $(TARGET) $(OBJS)
# 模式匹配规则:当make需要目标 xyz.o 时,自动生成一条 xyz.o: xyz.c 规则:
%.o: %.c
@echo 'compiling $<...'
cc -c -o $@ $<
clean:
rm -f *.o $(TARGET)
上面的Makefile就是执行world.out: hello.o main.o的时候,发现没有hello.o文件,于是需要查找以hello.o为目标的规则,结果匹配到模式规则%.o: %.c,于是make自动根据模式规则为我们动态创建了规则。
hello.o: hello.c
@echo 'compiling $<...'
cc -c -o $@ $<
Makefile的常用函数wildcard和patsubst
make提供了很多内置函数,比如wildcard、patsubst等,用于对文件名进行匹配、替换等操作。
wildcard
SRC = $(wildcard pattern)查找当前目录下所有符合模式pattern的文件。
SRC=$(wildcard *.c)
查找当前目录下所有.c后缀的文件赋值给SRC,例如当前目录有main.c hello.c,那么SRC=main.c hello.c
patsubst
$(patsubst pattern, replacement, text)将text中符合pattern的部分替换为replacement。
OBJS = $(patsubst %.c,%.o,$(wildcard *.c))
将目录中所有的.c文件替换为.o
自动生成依赖
上面说的隐式规则和模式规则,可以解决自动将.c文件编译为.o文件,但是无法解决.c文件依赖.h文件的问题。
因为.c依赖那些.h需要查看内容才能知道。
但是要识别.c文件的头文件依赖,可以用GCC提供的-MM参数:
$ gcc -MM main.c
main.o: main.c hello.h
因此我们利用GCC的这个功能,对每个.c文件都生成一个依赖项,通常我们把它保存到.d文件中,再用include引入到Makefile中。
# 列出所有 .c 文件:
SRCS = $(wildcard *.c)
# 根据SRCS生成 .o 文件列表:
OBJS = $(SRCS:.c=.o)
# 根据SRCS生成 .d 文件列表:
DEPS = $(SRCS:.c=.d)
TARGET = run.out
# 默认目标:
$(TARGET): $(OBJS)
$(CC) -o $@ $^
# main.d 的规则由 main.c 生成:
%.d: %.c
rm -f $@; \
$(CC) -MM $< >$@.tmp; \
sed 's,\($*\)\.o[ :]*,\1.o $@ : ,g' < $@.tmp > $@; \
rm -f $@.tmp
# 模式规则:
%.o: %.c
$(CC) -c -o $@ $<
clean:
rm -rf *.o *.d $(TARGET)
# 引入所有 .d 文件:
include $(DEPS)
通过include $(DEPS)我们引入hello.d和main.d文件,但是这两个文件一开始并不存在
相关文章
线程池
线程池的原理 我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题:如果并发得线程数量很多,并且每个线程都是执行一个时间很短得任务结束了,这样频繁得创建线程会降低系统的效率,因为频繁创建线程和销毁线程需要时间。 线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。线程池线程都是后台线程。每个线程都可以默认得堆栈大小,以默认优先级运...
线程同步
线程同步的概念 多个线程对内存中的共享资源访问时,让线程进行线性的方式,有顺序的访问。线程对内存的这种访问方式就是线程同步。 下面是一个两个线程同时对变量num,进行加1的操作的demo,但是最终结果与预想结果,有很大差异。下面我们将分析并解决线程同步的问题。 ``` #include <pthread.h> #include <stdio.h> #include <unistd.h> #...
多线程与线程同步
多线程特点 线程是轻量级的进程,在Linux环境下线程的本质仍是进程。在计算机上运行的程序是一组指令及指令参数的组合,指令按照既定的逻辑控制计算机运行。操作系统会以进程为单位,分配系统资源。 可以理解为:进程是资源分配的最小单位,线程是操作系统调度的最小单位。 在概念上了解线程与进程的区别: - 进程有自己独立的地址空间,多个线程共用一个地址空间 - 线程更加节省系统资源,效率不...